
Vibe Coding vs Spec-Driven Development
Why most AI-built software works in demos but breaks in production

I’m Sergio Pereira, and this is my newsletter 👋
Last week I wrote about how the bottleneck in software moved from writing code to deciding what to build and how to build it. That’s what’s driving the rise of the Product Engineer.

Some people have asked me, “ok great, I get the theory, but how does that work in practise?”. Indeed, I think very few Software Engineers, and especially engineering teams, have upgraded their processes to actually reap the opportunity presented to us by LLMs and all these powerful tools.
Today I’m writing about that. The difference between the so called “Vibe Coding” process and a structured production-level AI-assisted software development. And for that I’m explaining my own process, and what changed vs a few years ago.
The fact is that right now, almost all Software Engineers and teams are experimenting with AI tools, and most of them start the same way: We describe what we want to Cursor or Copilot. We iterate with prompts, and tweak until it works.
And to be fair, it does work pretty well many times. We can get to a proof of concept incredibly fast. Those urgent sales requests that used to be a nightmare, now we can ship a demo in the same day. A landing page, a feature, even a full app that looks functional at first glance can be much faster than before.
The problem is what happens next. We start testing a bit more thoroughly, and edge cases show up, the flows break. We realise the logic in inconsistent. Small changes create unexpected side effects somewhere else in the system.
And suddenly we’re in a place that feels very familiar to anyone who has tried to debug one of these “vibe coded” apps. We don’t understand what’s there, we don’t trust that code. And ultimately it’s not tools’ fault, it’s not even that the code is bad. The core issue is that the system was not well enough defined before building, and you end up with something that might be good for demos, but which is not ready for production.
AI made it very easy to build something that works once. It did not make it easy to build something that works reliably in production.
This is where the distinction becomes important.
Vibe Coding looks like this:
We describe what we want
We iterate with prompts
We tweak until it works
It feels fast and intuitive. And it’s a great way to explore ideas and build proof of concept type code. However, it has those shortcomings. A diagram for Vibe Coding looks something like this:
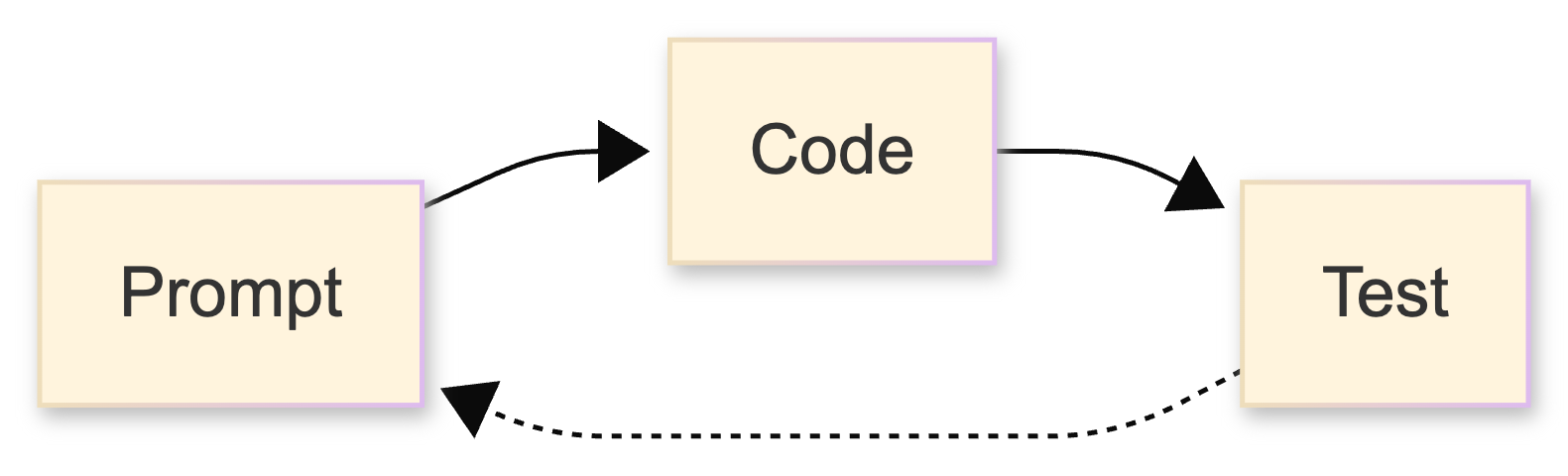
That’s why the best Software Engineers, and especially those taking a Product Engineer approach, they take a different approach.
The emerging name for it is Spec-Driven Development, and it looks like this:
You define the engineering standards (tech.md)
You write down the functional requirements (several feature.md)
Down to the detail of acceptance criteria, edge cases to be tested, etc
You include all that (the “specs”) in the actual code repo
Then you use AI tools to write the code to implement all that. The code generated will not simply “work”. It will fulfil the functional requirements you defined plus follow the engineering standards you want (like tech stack, approach to testing, logging, etc etc). And above all, it’s deterministic. You get code that matches your specs. If something doesn’t work, you can simply review the spec, because often we forget some edge case or challenge some earlier assumption.
Looks something like this:

Both approaches can get us to a working demo, but only one reliably gets us to production-ready code. Because the difference is not speed, it’s determinism.
Vibe coding creates systems that behave probabilistically. They work most of the time, until they don’t.
Spec-driven development creates systems that behave deterministically. You know what should happen for a given input, and you can verify that it does.
Once you see Software Development this way, it becomes hard to unsee. And that’s also why the best Product Engineers don’t just prompt, they spend most of their time thinking, defining and constraining the system before any code is written.
That’s where the leverage is now. If that job is properly done, writing the code can nowadays be 100% written by AI, regardless of the actual tool (Cursor, Copilot, Codex, Claude Code, etc) as long as you use one of the latest models, such as Claude Opus 4.6.
My own development workflow changed a lot because of this. A few years ago, I would start coding early. I’d get a rough idea of the feature, start coding, and figure out edge cases along the way. The fact that teams are usually broken into product + tech as separate people/teams didn’t help, since the Engineers (myself and my teams included) didn’t always fully understand the functional requirements written in a ticket. Starting and figuring out edge cases along the way was actually needed to gain that context and understanding to a point where we could challenge assumptions and even spot mistakes in those functional requirements.
The process was broken, and in most teams it was not a fault of the individual Engineers, but rather a by-product of orgs that were designed around the key constraint that transforming a ticket into a pull request took most of the time in a software development life cycle. I’m certainly to blame for such decisions in the past, I reckon that my process wasn’t optimal.
However, writing code is no longer the bottleneck. So today that approach is silly, especially because most people are using AI tools to code anyway. And we’ve all tried to debug a vibe-coded app, and it’s not fun. We’re chasing behavior that was never clearly defined in the first place.
So now my process is almost the opposite, I spend most of my time upfront on the spec. I start with the problem and the workflow, I try to understand what we are actually trying to achieve, not just what was initially requested. That often means going back to the business, looking at data more carefully, or simply asking better questions.
And interesting sign of the times we live in, nowadays in my engagements I always own product and tech, as one unit. In some clients I even get a “Fractional CTPO” title instead of “Fractional CTO” (“P” is for product, in case you’re wondering) to make that explicit. I guess that’s C-level version of the “Product Engineer”.
That means I have exposure to the company’s Founders, to clients/users, to my sales and marketing colleagues, to lawyers (I work a lot in fintech and healthcare, where legal boundaries for agents and human in the loop are important to not overstep), and to anyone else relevant to help me figure out what to build and how to build it.
I have meetings, chats, email threads, etc etc with those stakeholders, I look into product usage data, bug reports and whatnot. LLMs are great to help an individual crunch that much data into signal, I built my own personal tools for this, and I often spend several days circling around a feature to get all the context needed for the spec. I write the spec and iterate it as I go through that process. Inputs, outputs, rules, constraints, expected behavior, etc. I try to make it all explicit in the spec.
Once I have a solid version, I actually use an LLM to review the spec itself. I ask it to challenge assumptions, point out missing edge cases, ask questions I didn’t think of. It’s the same concept as a code review, but before any code is written.
Only after this do I move to implementation. At that point, writing the code is often the easiest part. Whether I’m using Cursor, Copilot or Claude Code, as long as I’m using one of the latest models, it’s very common to get a correct implementation in one shot, even for fairly complex features. I leave my agents producing the code through the day and over night, usually takes some hours or a full day.
Then I test. And I still review the key parts of the code to make sure it actually follows the spec I defined. The difference is that I’m no longer discovering what the system should do while I’m coding it. That work is already done.
This is the workflow I’ve been using with clients and in my own projects, and it’s also what I’ve been teaching recently. My friends at GenAI Works invited me to lecture a cohort-based course where I break this down step by step, and I accepted.
It’s called Ship Reliable Software Faster with AI and I go through the full Spec-Driven Development process, from idea to production, focusing on how to use AI without creating chaos, and how to structure software systems so they behave reliably.
They helped me make it for busy professionals, and I packed all the content into 4 hands on sessions, where you go from idea to deployed app in just a few hours, and more importantly you’ll be equipped to use this process in your job or in your startup.
Most people don’t work like this yet. Not because they’re not capable, but because the tools make it very tempting to skip the hard parts. It feels productive to jump from prompt to prompt. It feels slower to sit down and write a proper spec.
But that’s exactly where the shift is.
So, even if you don’t join my course, please start writing proper specs for the products and features you ship, but in your job and in your personal projects. It’s the simplest change you can make, and it will completely change how you build. Thank me later :)
If you’re already implementing Spec-Driven Development in your team, reach out and let me know how it is working for you, I love discussing this stuff. Drop me a DM on Linkedin.
See you next Friday,
Sergio Pereira
I will try this. I usually just write on one spec that I typically name 'plan.md', then feed it to the LLM. I also try to go through the generated code, just in case. There was a time an LLM added a short timeout to my HTTP client (axios) config, and I didn't see it. I was embarrassed when I eventually found out why some HTTP requests were failing for no reason.